WotC fucked around, and WotC found out. I hope that some of those sales actually convert into longer term customers for all these companies. #ttrpg
The Stochastic Game
Ramblings of General Geekery
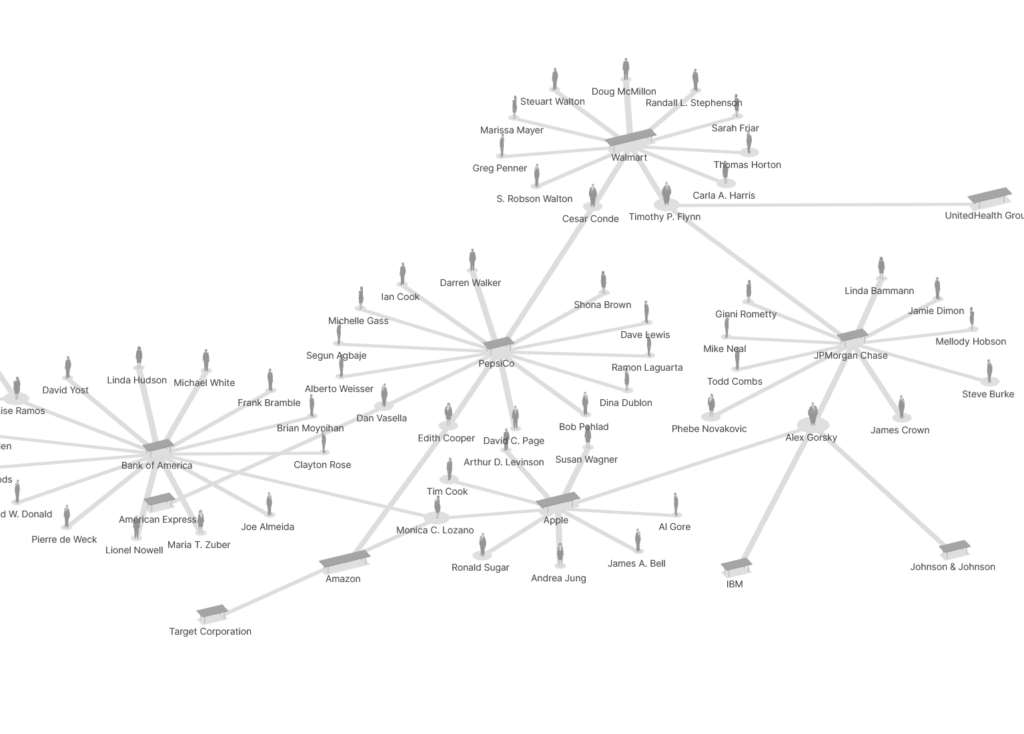
They Rule: this visualizer for who sits on what big corp’s board of directors (and how they’re all linked) is really neat.
I’ve seen a few explainers about why dialogue has become unintelligible in modern cinema and TV, but this one hits all the highlights in a concise way:
Judging from the sustained rise in Mastodon activity over the past month, it looks like people might actually be serious about this shit this time? Fingers crossed.
Oh wow first they killed third party apps, and now they completely fucked up TweetDeck because they don’t understand how people used it. My Twitter usage is gonna go way the fuck down.
Dealing with Metaplots in TTRPGs

“Metaplot” is often a dirty word around TTRPG players, and I just don’t understand this negative attitude. Here are some ways to deal with them (the metaplots, not the players with a negative attitude), all of which I’ve done to some degree or another except the last option.
I’ve only just started reading the Mahabharata and there’s already crazy body horror with a blind woman giving birth to a giant pile of monstrous flesh which explodes in a hundred embryos that are later put in jars to gestate. This is wild!

Yum. Pancakes.


The Marshall mini fridge is apparently a thing that exists, so of course my band’s guitar player wants one for our jam space…

Haha the commentators who said the first OGL was irrevocable are of course coming up with more commentary about the future of D&D and TTRPGs. Nope, sorry, not gonna listen again